Code
import numpy as np
import pandas as pd
import matplotlib.pyplot as pltIn this final chapter, you will learn about more advanced hyperparameter tuning methodologies known as ‘’informed search’’. A coarse-to-fine methodology is included as well as Bayesian & Genetic hyperparameter tuning algorithms. You will learn how informed search differs from uninformed search as well as gain practical skills with each of the methodologies, comparing and contrasting them along the way.
This Informed Search is part of Datacamp course: Hyperparameter Tuning in Python Hyperparameters play a significant role in the development of powerful machine learning models. However, with increasingly complex models with numerous options available, how can you efficiently identify the best settings for your particular issue? You will gain practical experience using some common methodologies for automated hyperparameter tuning in Python using Scikit Learn. Among these are Grid Search, Random Search, and advanced optimization methodologies such as Bayesian and Genetic algorithms. To dramatically increase the efficiency and effectiveness of your machine learning model creation, you will use a dataset predicting credit card defaults.
This is my learning experience of data science through DataCamp. These repository contributions are part of my learning journey through my graduate program masters of applied data sciences (MADS) at University Of Michigan, DeepLearning.AI, Coursera & DataCamp. You can find my similar articles & more stories at my medium & LinkedIn profile. I am available at kaggle & github blogs & github repos. Thank you for your motivation, support & valuable feedback.
These include projects, coursework & notebook which I learned through my data science journey. They are created for reproducible & future reference purpose only. All source code, slides or screenshot are intellactual property of respective content authors. If you find these contents beneficial, kindly consider learning subscription from DeepLearning.AI Subscription, Coursera, DataCamp
import numpy as np
import pandas as pd
import matplotlib.pyplot as pltYou’re going to undertake the first part of a Coarse to Fine search. This involves analyzing the results of an initial random search that took place over a large search space, then deciding what would be the next logical step to make your hyperparameter search finer.
def visualize_hyperparameter(name):
plt.clf()
plt.scatter(results_df[name],results_df['accuracy'], c=['blue']*500)
plt.gca().set(xlabel='{}'.format(name), ylabel='accuracy', title='Accuracy for different {}s'.format(name))
plt.gca().set_ylim([0,100])from itertools import product
max_depth_list = range(1, 6)
min_samples_leaf_list = range(3, 14)
learn_rate_list = np.linspace(0.01, 1.33, 200)
combinations_list = [list(x) for x in product(max_depth_list,
min_samples_leaf_list,
learn_rate_list)]
results_df = pd.read_csv('dataset/results_df.csv')
# Confirm the size fo the combinations_list
print(len(combinations_list))
# Sort the results_df by accuracy and print the top 10 rows
print(results_df.sort_values(by='accuracy', ascending=False).head(10))
# Confirm which hyperparameters were used in this search
print(results_df.columns)
# Call visualize_hyperparameter() with each hyperparameter in turn
visualize_hyperparameter('max_depth')11000
max_depth min_samples_leaf learn_rate accuracy
1 10 14 0.477450 97
4 6 12 0.771275 97
2 7 14 0.050067 96
3 5 12 0.023356 96
5 13 11 0.290470 96
6 6 10 0.317181 96
7 19 10 0.757919 96
8 2 16 0.931544 96
9 16 13 0.904832 96
10 12 13 0.891477 96
Index(['max_depth', 'min_samples_leaf', 'learn_rate', 'accuracy'], dtype='object')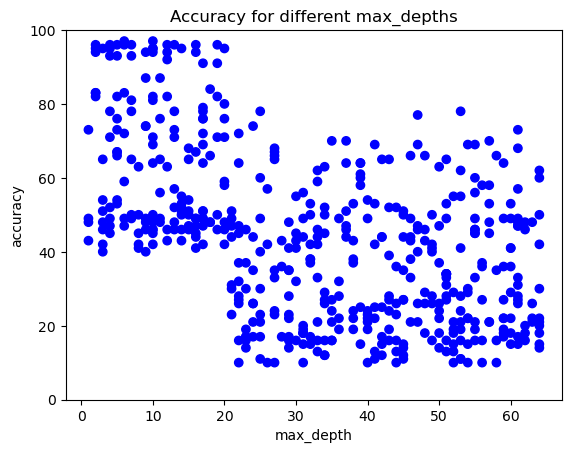
visualize_hyperparameter('min_samples_leaf')
visualize_hyperparameter('learn_rate')
print("\nWe have undertaken the first step of a Coarse to Fine search. Results clearly seem better when max_depth is below 20. learn_rates smaller than 1 seem to perform well too. There is not a strong trend for min_samples leaf though")
We have undertaken the first step of a Coarse to Fine search. Results clearly seem better when max_depth is below 20. learn_rates smaller than 1 seem to perform well too. There is not a strong trend for min_samples leaf thoughYou will now visualize the first random search undertaken, construct a tighter grid and check the results.
def visualize_first():
for name in results_df.columns[0:2]:
plt.clf()
plt.scatter(results_df[name],results_df['accuracy'], c=['blue']*500)
plt.gca().set(xlabel='{}'.format(name), ylabel='accuracy', title='Accuracy for different {}s'.format(name))
plt.gca().set_ylim([0,100])
x_line = 20
if name == "learn_rate":
x_line = 1
plt.axvline(x=x_line, color="red", linewidth=4)visualize_first()
def visualize_second():
for name in results_df2.columns[0:2]:
plt.clf()
plt.scatter(results_df[name],results_df['accuracy'], c=['blue']*500)
plt.gca().set(xlabel='{}'.format(name), ylabel='accuracy', title='Accuracy for different {}s'.format(name))
plt.gca().set_ylim([0,100])
x_line = 20
if name == "learn_rate":
x_line = 1
plt.axvline(x=x_line, color="red", linewidth=4)max_depth_list = list(range(1, 21))
learn_rate_list = np.linspace(0.001, 1, 50)
results_df2 = pd.read_csv('dataset/results_df2.csv')
visualize_second()

In this exercise you will undertake a practical example of setting up Bayes formula, obtaining new evidence and updating your ‘beliefs’ in order to get a more accurate result. The example will relate to the likelihood that someone will close their account for your online software product.
These are the probabilities we know:
7% (0.07) of people are likely to close their account next month 15% (0.15) of people with accounts are unhappy with your product (you don’t know who though!) 35% (0.35) of people who are likely to close their account are unhappy with your product
p_unhappy = 0.15
p_unhappy_close = 0.35
# Probability someone will close
p_close = 0.07
# Probability unhappy person will close
p_close_unhappy = (p_unhappy_close * p_close) / p_unhappy
print(p_close_unhappy)0.16333333333333336In this example you will set up and run a bayesian hyperparameter optimization process using the package Hyperopt. You will set up the domain (which is similar to setting up the grid for a grid search), then set up the objective function. Finally, you will run the optimizer over 20 iterations.
You will need to set up the domain using values:
Note that for the purpose of this exercise, this process was reduced in data sample size and hyperopt & GBM iterations. If you are trying out this method by yourself on your own machine, try a larger search space, more trials, more cvs and a larger dataset size to really see this in action!
from sklearn.model_selection import train_test_split
credit_card = pd.read_csv('dataset/credit-card-full.csv')
# To change categorical variable with dummy variables
credit_card = pd.get_dummies(credit_card, columns=['SEX', 'EDUCATION', 'MARRIAGE'], drop_first=True)
X = credit_card.drop(['ID', 'default payment next month'], axis=1)
y = credit_card['default payment next month']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, shuffle=True)import hyperopt as hp
from sklearn.ensemble import GradientBoostingClassifier
from sklearn.model_selection import cross_val_score
# Set up space dictionary with specified hyperparamters
space = {'max_depth': hp.hp.quniform('max_depth', 2, 10, 2),
'learning_rate': hp.hp.uniform('learning_rate', 0.001, 0.9)}
# Set up objective function
def objective(params):
params = {'max_depth': int(params['max_depth']),
'learning_rate': params['learning_rate']}
gbm_clf = GradientBoostingClassifier(n_estimators=100, **params)
best_score = cross_val_score(gbm_clf, X_train, y_train,
scoring='accuracy', cv=2, n_jobs=4).mean()
loss = 1 - best_score
return loss
# Run the algorithm
best = hp.fmin(fn=objective, space=space, max_evals=20,
rstate=np.random.RandomState(42), algo=hp.tpe.suggest)
print(best)ModuleNotFoundError: No module named 'hyperopt'You’re going to undertake a simple example of genetic hyperparameter tuning. TPOT is a very powerful library that has a lot of features. You’re just scratching the surface in this lesson, but you are highly encouraged to explore in your own time.
This is a very small example. In real life, TPOT is designed to be run for many hours to find the best model. You would have a much larger population and offspring size as well as hundreds more generations to find a good model.
You will create the estimator, fit the estimator to the training data and then score this on the test data.
For this example we wish to use:
from tpot import TPOTClassifier
# Assign the values outlined to the inputs
number_generations = 3
population_size = 4
offspring_size = 3
scoring_function = 'accuracy'
# Create the tpot classifier
tpot_clf = TPOTClassifier(generations=number_generations, population_size=population_size,
offspring_size=offspring_size, scoring=scoring_function,
verbosity=2, random_state=2, cv=2)
# Fit the classifier to the training data
tpot_clf.fit(X_train, y_train)
# Score on the test set
print(tpot_clf.score(X_test, y_test))You will now see the random nature of TPOT by constructing the classifier with different random states and seeing what model is found to be best by the algorithm. This assists to see that TPOT is quite unstable when not run for a reasonable amount of time.
tpot_clf = TPOTClassifier(generations=2, population_size=4, offspring_size=3,
scoring='accuracy', cv=2, verbosity=2, random_state=42)
# Fit the classifier to the training data
tpot_clf.fit(X_train, y_train)
# Score on the test set
print(tpot_clf.score(X_test, y_test))NameError: name 'TPOTClassifier' is not definedtpot_clf = TPOTClassifier(generations=2, population_size=4, offspring_size=3,
scoring='accuracy', cv=2, verbosity=2, random_state=122)
# Fit the classifier to the training data
tpot_clf.fit(X_train, y_train)
# Score on the test set
print(tpot_clf.score(X_test, y_test))NameError: name 'TPOTClassifier' is not definedtpot_clf = TPOTClassifier(generations=2, population_size=4, offspring_size=3,
scoring='accuracy', cv=2, verbosity=2, random_state=99)
# Fit the classifier to the training data
tpot_clf.fit(X_train, y_train)
# Score on the test set
print(tpot_clf.score(X_test, y_test))NameError: name 'TPOTClassifier' is not defined